Using Data from Digitised Newspapers
This project uses data from Wikidata to provide a list of newspapers published during the lifetime of a chosen person. The goals of the project are to provide a list of newspapers available in eluxemburgensia.lu adhering to the given criteria, provide a link to the selected newspapers on the eluxemburgensia.lu website and demonstrate how to use both the Wikidata Application Programming Interface (API) and the eluxemburgensia.lu data in a simple project.
Wikidata provides the data storage for Wikimedia projects, including Wikipedia. It can be read by machines (and humans!) and thus, provides a means to query data from Wikipedia through code using its publicly available API.
The BnL provides information about digitised newspapers and serials available on the eluxemburgensia.lu portal as a list in json format with details about each publication. This includes the main metadata date of each title, but not any full text. We will use the publication start and end dates to determine if the newspaper should be selected for inclusion in the final results.
Jupyter Lab is used to encapsulate all the information regarding the project in a single notebook and Python is used as the programming language. The Jupyter notebook is available on GitHub: https://github.com/natliblux/OpenBnL-eluxembourgensia.
The project consists of six steps:
- Requesting a name from the user;
- Retrieving the entries in Wikidata that correspond to that name;
- If more than one response, requesting the user to select one entry from the list of results;
- Retrieving the birth and death dates of the chosen entry;
- Selecting the newspapers published during that time period;
- Displaying the results.
Requesting a name from the user
Requesting and receiving input from the user is a simple call to the input method. A while loop is used to ensure that the user provides data rather than just pressing Enter.
# Request a name from the user
name = ''
while (name==''):
name = input("Enter a name to search for in Wikidata:")
if '' == name:
print('Please enter a name.')
Once data has been entered, we can then query Wikidata to find entries relating to that data. In this case, we will search Wikidata for “Jean-Claude Juncker”.
Retrieving the entries in Wikidata that correspond to that name
The Wikidata API is available to use from this URL: https://www.wikidata.org/w/api.php. This same URL provides a help page with information regarding the available functions.
At the beginning of our Jupyter Lab Notebook, a simple function is defined that will encapsulate the call to the Wikidata API. This allows us to capture any errors that may occur.
def fetch_wikidata(params):
url = 'https://www.wikidata.org/w/api.php'
try:
return requests.get(url, params=params)
except:
return 'ERR'
To use this function, we simply setup the required parameters and then call the function.
# Build the wikidata parameters
# Call wbsearchentities function with our name to search
# Output the results in English and using the json format
params = {
'action': 'wbsearchentities',
'format': 'json',
'search': name,
'language': 'en'
}
# Fetch the data from Wikidata
wikidata_results = fetch_wikidata(params)
# if no error, convert the response to JSON
if wikidata_results == 'ERR' or 'error' in wikidata_results.text:
print(wikidata_results.text)
else:
wikidata_results = wikidata_results.json()
As you can see, the action we want to perform is “wbsearchentities” which, as outlined on the API page, “Searches for entities using labels and aliases”. We request the results in json format and in English. The entry we want to search for is in the “search” parameter. If no errors are produced then the results can be converted into the Python dict format using the .json() function otherwise, the error message is displayed to the user.
Selecting one entry from a list of results
As the Wikidata API searches using labels and aliases, multiple entries could be found. If this is the case, we display the list to the user and ask them to choose one.
First, we define a function that will build the list to display to the user.
def selectFromDict(options):
index = 0
indexValidList = []
print('Select an option:')
for optionName in options:
index = index + 1
indexValidList.extend([options[optionName]])
print(str(index) + ') ' + optionName)
inputValid = False
while not inputValid:
inputRaw = input('Option: ')
inputNo = int(inputRaw) - 1
if inputNo > -1 and inputNo < len(indexValidList):
selected = indexValidList[inputNo]
inputValid = True
break
else:
print('Please select a valid option number.')
return selected
This function takes a list of options that contains a label and an identifier, numbers each option and then displays it to the user. Once the user selects a valid number, the function returns the selected entry.
options= {}
for entry in wikidata_results['search']:
label = entry['label']
id = entry['id']
options[label] = id
if len(options) > 1:
selected_id = selectFromDict(options)
else:
selected_id = id
for label, id in options.items():
if id == selected_id:
selected_entry = label
break
Select an option:
1) Jean-Claude Juncker
2) Jean-Claude Juncker kommentiert deutsch-polnisches Verhältnis
3) Jean-Claude Juncker wird Herausgeber des Rheinischen Merkur
4) Jean-Claude Juncker erhält den Karlspreis 2006
5) Jean-Claude Juncker zu den EU-Beitrittsverhandlungen mit der Türkei
Option: 1
As you can see, we build the options list by inserting each result from Wikidata with it’s label and unique identifier. If there is only a single option, then we select that one. Otherwise, we call the “selectFromDict” function to request the user to make a choice. Once we have their response, we take the selected entry to use in our next Wikidata query.
Retrieving the birth and death dates of the chosen entry
This time, when we call the function to query Wikidata we will use “wbgetentities” which retrieves data from a given entity. It can, in fact, be used to retrieve data from multiple entities but we will use it to retrieve only a single entity.
# Retrieve the birth and death date from wikidata for the given id
# Create parameters
params = {
'action': 'wbgetentities',
'ids':selected_id,
'format': 'json',
'languages': 'en'
}
# fetch the API
wikidata_selected_entry = fetch_wikidata(params)
# Convert the response to JSON
if wikidata_selected_entry != 'ERR':
wikidata_selected_entry = wikidata_selected_entry.json()
As before, to setup the parameters, we specify the action we want to perform, the format for the results and the language. This time, we provide the Wikidata identifier for the chosen entity.
Selecting the newspapers published during that time period
Now that we have retrieved the data about the chosen entity, we want to obtain the birth and death dates and then filter our list of newspapers.
First, we can’t be sure that the chosen entity will have a birth and death date. It could be that the user chose an entity that is not a person. Therefore, we first check if the data exists before retrieving it. If it doesn’t exist, after informing the user, we set fictitious dates in order not to provoke errors later on in our code.
# P569 = birth date
if 'P569' in wikidata_selected_entry["entities"][selected_id]["claims"]:
birthdate = wikidata_selected_entry["entities"][selected_id]["claims"]["P569"][0]["mainsnak"]["datavalue"]["value"]["time"]
# parse out the date as yyyy-mm-dd
birthdate = birthdate[1:11]
else:
print("No birthdate is available in the given entry. A default birthdate of '2025-01-01' will be used. " \
+ "The process will continue but the results will not be very relevant.")
birthdate = "2025-01-01"
# P570 = death date
if 'P570' in wikidata_selected_entry["entities"][selected_id]["claims"]:
deathdate = wikidata_selected_entry["entities"][selected_id]["claims"]["P570"][0]["mainsnak"]["datavalue"]["value"]["time"]
deathdate = deathdate[1:11]
print_deathdate = deathdate
else:
deathdate = "9999-12-31"
print_deathdate = ""
In order to be able to display the death date to the user in our final result, we use a variable called “print_deathdate” which will either display the real death date of the chosen entity or nothing at all. It doesn’t make sense to display the default death date (9999-12-31) to the user in the final result.
As you can see, Wikidata uses properties to define each of its data points. The full list can be found here. In that list, you can see that P569 is the date of birth and P570 is the date of death.
Now that we have the birth and death dates, we can request the list of newspapers in the digital collection and filter it. The list of newspapers is available here.
# get the BnL eluxemburgensia collection
elux_collection = requests.get("https://viewer.eluxemburgensia.lu/api/viewer2/cms/digitalcollections")
elux_collection = elux_collection.json()
To select the newspapers published between the birth and death dates of our chosen entity, we must ensure that the publishing end date is after the birth date and the publishing start date is before the death date. Therefore, we loop through our list and preform this comparison. If the result is true, we add the newspaper to this list to be displayed. Again, if there is no publishing end date, we use the default date of “9999-12-31”.
filtered_newspapers = []
for newspaper in elux_collection["data"]:
newspaper_dict = {}
startdate = newspaper["startdate"]
try:
enddate = newspaper["enddate"]
print_enddate = enddate
except:
enddate = "9999-12-31"
print_enddate = ""
if startdate <= deathdate and enddate >= birthdate:
newspaper_dict = {'Title': newspaper["title"],'Start Date': startdate, 'End Date': print_enddate, 'Link': "https://persist.lu/" + newspaper["ark"]}
filtered_newspapers.append(newspaper_dict)
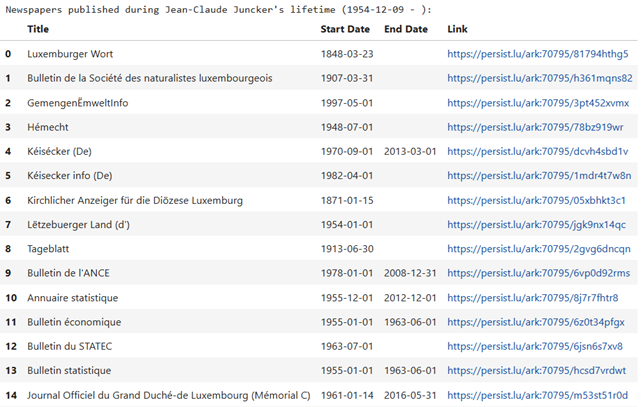
Displaying the results
In order to display the results in a formatted readable fashion, the Python library “pandas” is used.
df = pd.DataFrame(filtered_newspapers, columns=["Title", "Start Date", "End Date", "Link"])
def make_clickable(val):
return f'<a target="_blank" href="{val}">{val}</a>'
dfStyler = df.style.set_properties(**{'text-align': 'left'})
dfStyler.set_table_styles([dict(selector='th', props=[('text-align', 'left')])])
dfStyler.format({'Link': make_clickable})
As you can see, it is a simple case of creating a pandas DataFrame providing the list of filtered newspapers and the column headings. We can then set a few formatting options:
- Left align all the columns;
- Left align the table headings;
- Make the link clickable.
The end result is: