Open source software, tools & libraries
Our data has been produced using state of the art technologies and standards. Through international standards, we can reach a wider audience, maximize the reusability of the data and support long-term preservation goals.
However, cultural heritage data can be daunting at first for some users. For this reason, the BnL started open sourcing software that has been internally developed to work with that data. Check out the BnL on GitHubBnLMetsExporter
This tool
is a Command Line Interface (CLI) to export METS/ALTO documents to other
formats, such as Dublin Core XML files. It parses the raw data (METS and ALTO)
and extracts the full text and meta data of every single article, section,
advertisement.
Export Format
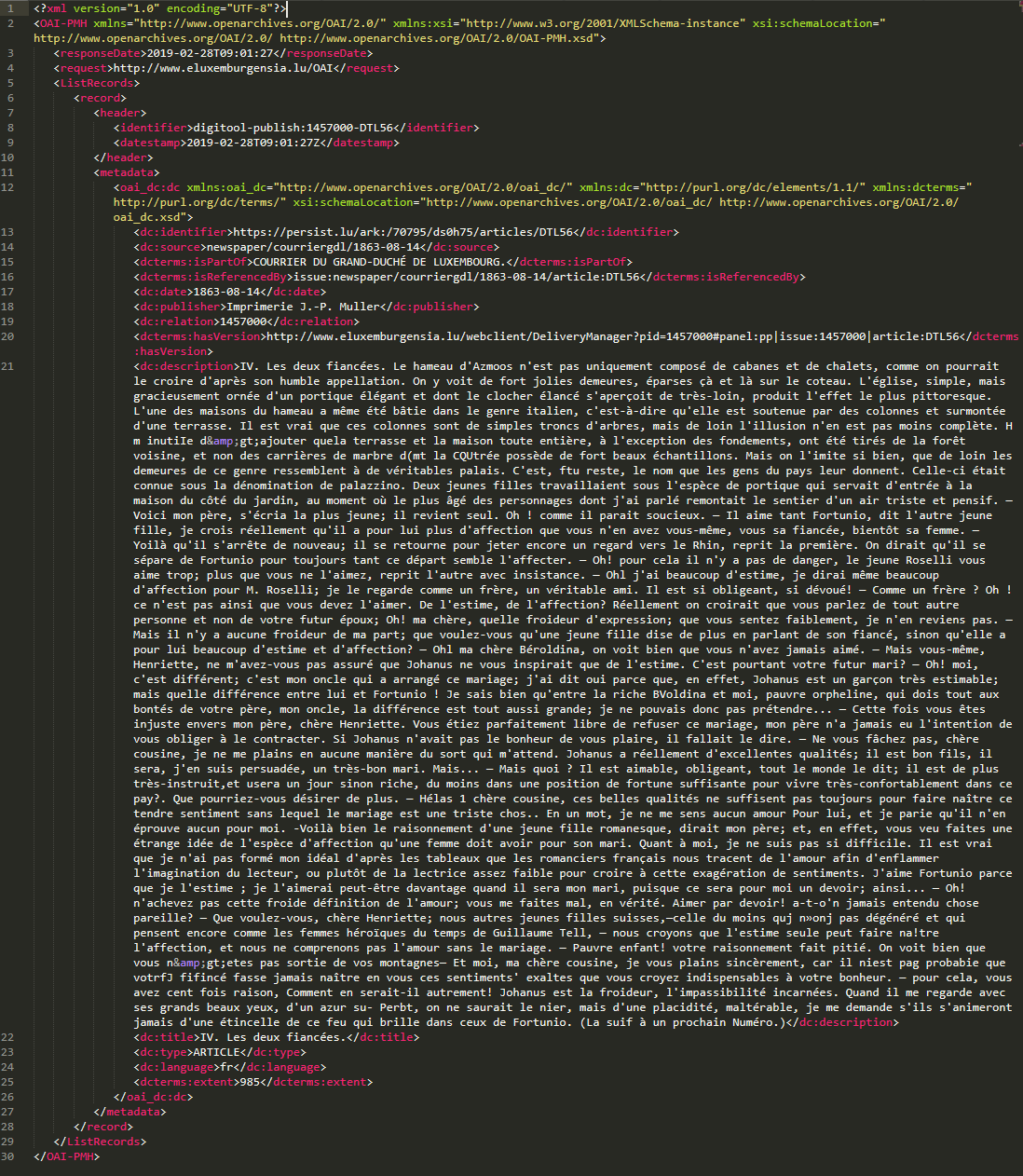
The default export XML-based and follows the Dublin Core format. The fields are described below. The Dublin Core data is wrapped in a OAI-PMH envelope. Every XML file corresponds to one article. The following sections will cover the most important tags.
<header>
This element contains a generated unique identifier (<identifier>) as well as a datestamp (<datestamp>) of when the data has been exported. It is not recomended to work with this identifier. Instead, use the value in <dc:identifier>.
<dc:identifier>
This is a unique and persistent identifier using ARK. The BnL is in the progress of transitioning to ARK. That is why PID-based identifiers are still provided in other fields.
<dc:source>
Describes the source of the document. For example
<dc:source>newspaper/luxwort/1848-12-15</dc:source> means that this article comes from the newspaper “luxwort” (ID for Luxemburger Wort) issued on 15.12.1848.<dcterms:isPartOf>
The complete title of the source document e.g. “Luxemburger Wort”.
<dcterms:isReferencedBy>
Another generated string that uniquely identifies the exported resource.
<dc:date>
The publishing date of the document e.g “1848-12-15”.
<dc:publisher>
The publisher of the document e.g. “Verl. der St-Paulus-Druckerei”.
<dc:relation>
The unique identifier of the parent document (e.g. newspaper issue), also referred to as PID.
<dcterms:hasVersion>
The link to the BnLViewer on eluxemburgensia.lu to view the resource online.
<dc:title>
The main title of the article, section, advertisement, etc.
<dc:description>
The full text of the entire article, section, advertisement etc. It includes any titles and subtitles as well. The content does not contain layout information, such as headings, paragraphs or lines.
<dc:type>
The type of the exported data e.g. ARTICLE, SECTION, ADVERTISEMENT, …
<dc:language>
The detected language of the text.
<dcterms:extent>
The number of words in the <dc:description> field.
Nautilus-OCR
Command Line Interface tool aimed at enhancing the quality of original OCR data using Artificial Intelligence. The software inputs and outputs METS/ALTO packages.
Pipeline tools
Nautilus-OCR comes with a set of tools to support a METS/ALTO to METS/ALTO pipeline.
METS/ALTO
Nautilus-OCR includes an end-to-end METS/ALTO pipeline that can be configured to perform reprocessing TextBlock selection based on enhancement prediction.
Custom Model Training
Using proprietary data, different modules allow the training of custom models responsible for optical character and font class recognition, as well as for enhancement prediction.
Pre-Trained Models
The software package comes equipped with four models, pre-trained by BnL, that can be used out-of-the-box.
Ground Truth Dataset
Additionally, a dataset of more than 33k transcribed image/text pairs comes in the form of bnl-ocr-public. Extracted from public domain newspapers, the data is split in two font classes (antiqua & fraktur).
OCR Engine
Nautilus-OCR
is not limited to operate on original OCR data only. The tool provides the
possibility to function as a regular OCR engine that can be trained and applied
on a set of images.

Read the papers
Combining Morphological and Histogram based Text Line Segmentation in the OCR Context
Text line segmentation is one of the pre-stages of modern optical character recognition systems. The algorithmic approach proposed by this paper has been designed for this exact purpose. Because of the promising segmentation results that are joined by low computational cost, the algorithm was incorporated into the OCR pipeline of the National Library of Luxembourg, in the context of the initiative of reprocessing their historic newspaper collection.

Rerunning OCR: A Machine Learning Approach to Quality Assessment and Enhancement Prediction
Iterating with new and improved OCR solutions enforces decision making when it comes to targeting the right candidates for reprocessing. This article captures the efforts of the National Library of Luxembourg to support those targeting decisions. They are crucial in order to guarantee low computational overhead and reduced quality degradation risks, combined with a more quantifiable OCR improvement.

Nautilus – An End-To-End METS/ALTO OCR Enhancement Pipeline
Enhancing OCR in a digital library not only demands improved machine learning models, but also requires a coherent reprocessing strategy in order to apply them efficiently in production systems. The newly developed software tool, Nautilus, fulfils these requirements using METS/ALTO as a pivot format. This paper covers the creation of the ground truth, the details of the reprocessing pipeline, its production use on the entirety of the BnL collection, along with the estimated results.
