Open Standards
Every document has been digitised using international and open standards, such as TIFF, XML, METS et ALTO.
High Quality Data
All available data have been quality checked and are used in production at the BnL. The datasets contain high quality metadata, ready to be used by you.
Clear Copyright
We take copyright very seriously and publish datasets where all the details have been resolved. That way, we can clearly communicate how you can use the data.
High Quality Digitisation Data
The BnL has digitised over 800.000 pages of Luxembourg newspapers. From those, more than 700.000 pages have rich metadata using international XML standards such as METS and ALTO.
Rich Metadata for Rich Usage
Digitising newspapers and books is challenging due to the nature of the documents. Newspapers, for instance, have complex layouts and structures that requires flexibility in the description of the different elements. The METS standard enables the precise description of the physical as well as the logical structure of a digital object. ALTO contains the OCR results, including the coordinates of each word on the page. METS and ALTO are the industry standard for the digitisation of complex documents such as newspapers and books. Those two XML standards are maintained by the Library of Congress.
What is METS?What is ALTO?Fine-Grained Segmentation
The strong point of METS / ALTO is the ability to segment documents into their core components. For newspapers, it means that we can select individual articles, sub-articles and even paragraphs.
Complete OCR
Every page is fully digitised. All the text is stored in the ALTO files and referenced back in the METS file. Additionally, every title, subtitle and caption have been manually corrected for increased quality.
Rich with Metadata
Next to the physical and logical structure, the data also contains numerous additional metadata related to the digitised document and to its associated files.

Download a Dataset & Start Exploring!
Multiple datasets are available for download. Each one is of different size and contains different newspapers. All the digitised material can also be found on our search platform a-z.lu (Make sure to filter by “eluxemburgensia”). All datasets contain XML (METS + ALTO), PDF, original TIFF and PNG files for every newspaper issue.
STARTER PACK
250MB
of digitised newspapers
- 5 days of news
- 5 newspaper issues
- 22 pages
- D’Wäschfra (1868)
- Public Domain, CC0 (See copyright notice)
- Best for getting started & developing
DEV PACK
3GB
of digitised newspapers
- 1 month of news
- 26 newspaper issues
- 112 pages
- Luxemburger Wort (1877)
- Public Domain, CC0 (See copyright notice)
- Best for getting started with Big Data
SAMPLE PACK
1GB
of digitised newspapers
- 11 different newspaper titles
- 1 issue per newspaper
- News between 1845 and 1877
- Public Domain, CC0 (See copyright notice)
- Best for testing different newspapers and metadata
Large Datasets
For advanced users, the BnL provides larger datasets. Those datasets are meant for data scientists and researchers, especially in the field of digital humanities where large quantity of data can train machine learning algorithms or neural networks. Note that you can combine all datasets to form an even larger set.
ML STARTER PACK
32GB
of digitised newspapers
- 1 year of news
- 304 newspaper issues
- 1220 pages
- L’indépendance Luxembourgeoise (1877)
- Public Domain, CC0 (See copyright notice)
- Best for getting started with machine learning
BIG DATA PACK
257GB
of digitised newspapers
- 10 years of news
- 2712 newspaper issues
- 10880 pages
- L’Union (1860-1869)
- Public Domain, CC0 (See copyright notice)
- Best for machine learning and deep neural networks
Processed Datasets
Working with the raw data can be tedious. For that reason, the BnL processed all newspapers and monographs that are in the public domain and extracted the full text and associated meta data of every single article, section, advertisement… The result is a large number of small, easy to use XML files formatted using Dublin Core. The same data is also available formatted as a single JSONL file with one line per article.
The open source tool of the BnL has been used to create the export. Documentation of the formatTEXT ANALYSIS PACK
2GB
of processed newspapers data
- 41 years of news (1841-1881)
- 25881 processed newspaper issues
- 106011 processed pages
- 592192 extracted articles
- Public Domain, CC0 (See copyright notice)
- Best for getting started with text analysis
Monograph TExt Pack
125MB
of processed monographs data
- 228 years period (1690-1918)
- 504 processed monographs
- 51709 processed pages
- 33477 extracted chapters
- Public Domain, CC0 (See copyright notice)
- Best for getting started with text analysis
OCR Datasets
As part of BnL’s AI strategy, we provide the ground truth data that falls into the public domain (CC0, see copyright notice). Available in two variations, the datasets cover historical newspapers published before 1878. The data is generally in German, French or Luxembourgish and has been manually corrected for a minimum accuracy of 99.95%.
GROUND TRUTH PACK
33.000
transcribed text lines
- Text line based OCR
- 19.000 text lines in Antiqua
- 14.000 text lines in Fraktur
- Transcribed using double-keying (99.95% accuracy)
- Public Domain, CC0 (See copyright notice)
- Best for training an OCR engine
RAW GROUND TRUTH Pack
1.700
text blocks
- Raw uncropped text blocks
- Pairs consist of block image and ALTO XML
- Public Domain, CC0 (See copyright notice)
- Best for testing/training text line segmentation
Are you a developer?
We have something for you.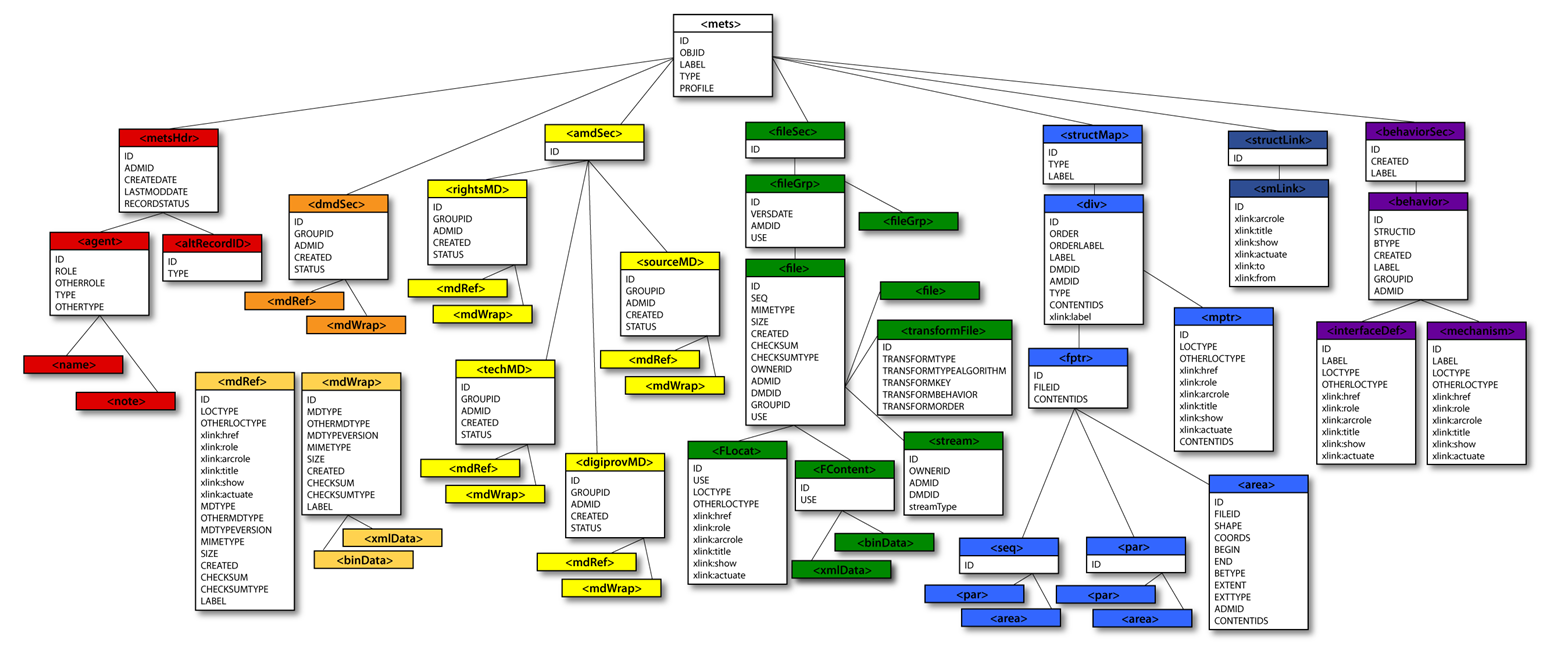
What is METS?
METS (Metadata Encoding and Transmission Standard) is a standard that allows the exchange of digitised documents between heritage institutions. It has been developed following the initiative of the Digital Library Federation (DLF) and is an implementation of the OAIS reference model (Model for an Open Archival Information System). Currently, the library of Congress in the United States of America is responsible for the maintenance of the METS schema. METS is an XML schema for the creation of digital objects. A digital object can be simple or complex, can consist of one or more digital files, which can be in different formats and describe detailed internal structure.
Visit METS on the Library of Congress websiteGet METS Primer (PDF)What is ALTO?
ALTO (Analyzed Layout and Text Object) is an XML standard created as a result of the European project METAe and is designed to represent a physical document in terms of page layout, word positions and much more. It is used to store information about the content and layout of physical documents. In particular, it is especially well suited to represent OCR results. The BnL uses ALTO together with METS. Each digitised page is represented by one ALTO file. ALTO files are responsible for the contents of individual pages and METS is responsible for the metadata, structural information and links between external files.
Visit ALTO on the Library of Congress website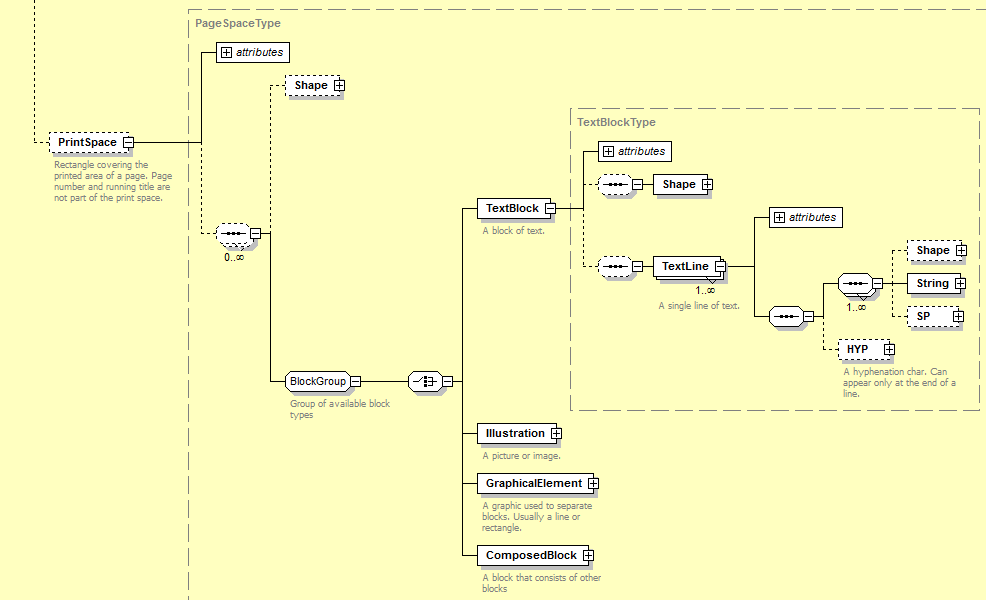
How does the BnL use METS / ALTO?
METS is an XML schema for the creation of digital objects. A digital object can be simple or complex, can consist of one or more digital files, which can be in different formats and describe detailed internal structure. The BnL created clear technical requirements and guidelines on how to use METS / ALTO.
METS File
Each document (newspaper issue or monograph) is modeled in 1 METS file. The file contains metadata, file sections as well as the physical and logical structures. The logical structure follows closely the requirements of the BnL. The METS file describes the relationship between the ALTO, PDF, TIFF, PNG and JPG files.
ALTO Files
Each scanned page goes through an OCR engine and the result is stored into the ALTO files via text blocks, lines and individual words with coordinates. The text blocks are linked inside the METS file.
PDF Files
We also have PDF files of every page and one PDF of the entire document also containing the table of contents. Every PDF contains the full text as an overlay and is fully searchable and selectable.
Original Images
Each page of the document is scanned and saved as a TIFF file with a resolution of 300 PPI. Since 2018, the BnL controls the quality of images using ISO/TS-19264-1.
ISO/TS-19264-1Black & White Images
Next to the other images, a high contrast black and white PNG image for each page is generated out of the original TIFF.
Thumbnails
Next to the other images, a smaller JPEG thumbnail for each page is generated as well.

BnL’s Technical Requirements
The National Library of Luxembourg wrote a complete technical document that describes all the requirements for all its digitisation projects. This includes aspects such as transport, image quality, rules for the logical structure, metadata requirements and contains numerous examples.
Download BnL’s Technical Requirements for Newspapers (21MB) Download BnL’s Technical Requirements for the Mémorial C (31MB)